By Arnab Dey
By Arnab Dey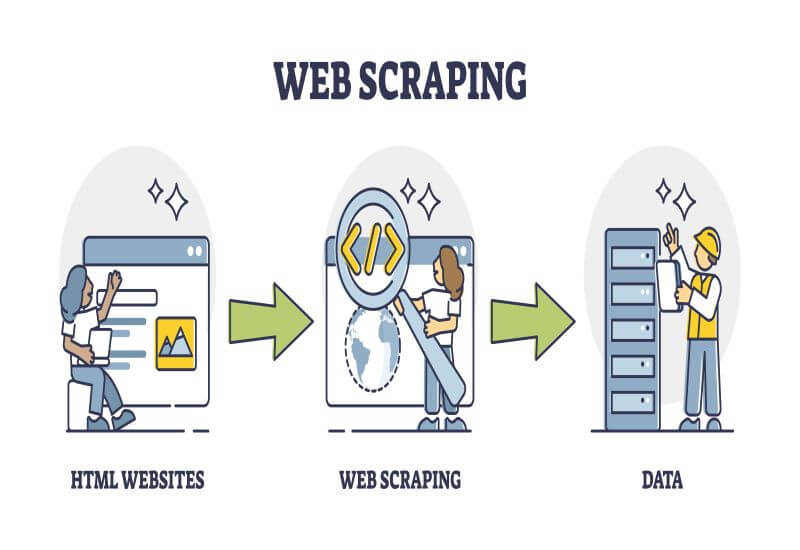
As web scraping becomes popular, it’s essential to make sure you’re doing it right. The process sounds easy to do, but there are many pitfalls that you might run into that can lead to unsatisfying results or even legal consequences if you accidentally commit a security violation.
Instead of brute-forcing it until you run out of unbanned proxies, you should think of better ways to get the data you need.
Whether you want to create a database of car crashes in specific coordinates or scrape the prices from e-retailers for comparison, here are the tips and tricks for effective and safe web scraping:
1. Plan Before You Scrape
Like other projects, web scraping with python requires proper planning to create a strategy before starting. First and foremost, you should determine the reason you need data. This may seem obvious, but your answer is the key to knowing what information you must gather.
How you’re going to use the gathered data is also crucial for planning. You can process it yourself, send it to a complex pipeline, or use the software. Your answer will be your first step to deciding the file format and structure for the gathered data.
Other ideas you need to sort out when planning may depend on what you’re trying to achieve. For instance, you may need data to improve your social media marketing strategies that will help you understand the current trends, user sentiments, feedback, and news.
However, unlike the typical website scraping tools, you may need the use of social media scraper bots to extract data from various social media platforms.
2. Use The Right Scraper For Your Specific Needs
These days, there are countless data scrapers to choose from, each with its own set of features. If you don’t figure out what type of data to scrape before buying one, you might end up wasting money on an option that doesn’t have the necessary features to get the job done.
This is why it’s important to have a full understanding of the type of data you should be scraping before making any purchase.
3. Limit The Speed Of Crawling

People mainly use web scrapers because they’re faster and more efficient than regular human data gathering. However, you have to remember that the quicker the bot crawls, the more load it puts on the website’s host.
If the website gets an excessive number of requests from your scraper at once, it might trigger a site crash, just like if the website was hit by a distributed denial-of-service DDoS attack. This is the main reason why many have anti-DDoS protection systems
By limiting your crawling speed, your scrapper will go undetected and allow it to gather the data you require. You may reduce the crawling speed by adding a delay of 10-20 seconds after crawling a few pages.
In addition, you can implement auto throttling mechanisms, which adjust the crawling speed based on your target website and load.
4. Respect The Website
Another effective web scraping trick is to respect the website you’re scraping. Before you scrape a website, spend time reading the robots.txt file of the website owner to determine what pages you can’t or can scrape from.
In other cases, it’ll also include information about at what frequency you can scrape the website.
Other than respecting the website, you must also respect the other users visiting the website. Intensive website scraping may put unnecessary load on the website’s host server, resulting in a poor web user experience.
This is a website scraping courtesy, and if you don’t respect such rules, you’ll end up getting blocked.
5. Avoid Scraping If You’re Asked To Login
Logging into a website gives you access to certain web pages that aren’t visible to the public. A good example is Facebook. Typically, you can only view two to three posts without logging in.
If you need to log in, you will receive requests to your website browser cookies to try to get access to the web page. This process makes it easier for websites to determine requests from the same address, increasing your chances of getting blocked. Thus, you should stop scraping data if you’re required to log in.
6. Try Using A Headless Browser

A headless browser is almost similar to typical web browsers, except it doesn’t have a premade user interface. To work on headless browsers effectively, you’ll need to implement a command line.
Browser environments are crucial for today’s websites to load. Website developers tend to use Javascript in many web-based apps these days, making it critical for users to have the means to execute and read them.
Websites built with Javascript have all of its hypertext markup language (HTML) hidden within the Javascript code’s lines. Unless web browsers are used, no HTML can be read, which means the website can’t be loaded. A regular web scraper might not have the functionality to go to such depths.
Users can also try building their browser-mimicking web scrapers from scratch. However, you should always seek help from professionals and act or you risk making something that might get you in trouble with the sites you’re scraping.
Bottom Line
Web scraping helps businesses enhance their strategies and determine what’s working for their competitors. Unfortunately, websites have integrated advanced anti-bot technologies to avoid scraping.
This means you need the best tips and tricks that increase your web scraper’s effectiveness. Keep the above strategies in mind to bypass every website’s anti-scraping measures and get the data you need.
Read Also: